
Editor’s note: With the continuous development of data recovery and digital forensics technology, techniques for forensic data recovery from the logic layer of hard drives are constantly improving. Yet there remains a great challenge: how to recover fragmented files? Through a case study of fragmented files in XFS file system, forensic experts from SalvationDATA will explain in this issue how to recover fragmented files based on XFS file system.
I Introduction to XFS File System
XFS is a 64-bit, high-performance log file system originally developed by Silicon Graphics Inc. in the early 1990s. It is highly scalable and robust and was transplanted into the Linux system by SGI.
XFS file system exceeds in data integrity and can ensure the consistency of file system data upon power failure and crash of the operating system. As long as the log function of the file system is on, data will not be damaged and can be recovered within a certain period of time in accordance with recorded logs irrespective of the total size and the number of data restored in the file system. Moreover, XFS is a 64-bit file system and supports the storage of millions of Tbytes data. Its excellence lies in its abilities to support the storage of both enormous and tiny sized files and numerous catalogs. The biggest file size supported by XFS is 263 = 9 exabytes.
II Storage Principle of XFS Files
Analysis of storage principles of XFS files revealed that allocation group is the one with the highest abstract degree among all the concepts used in the system. XFS file system is divided into multiple allocation groups (AG), which work as the equal-length linear storage area in the system. Each group manages its inode and free space, and files and folders can be stored cross groups. This mechanism provides the system with scalability and parallel features: multiple threads and processes can perform I/O operation simultaneously in the same file system. This internal partitioning mechanism brought by AG is highly useful when a file system spans across more than one physical devices and adds to the probability of optimizing the throughout utilization for subordinate storage components.
After an XFS file system is created on a disc, the disc will be formatted as shown in Picture 1.

Picture 1
Default set up of CentOS7 is to create 4 AGs, each of which is equivalent to a separate file system and maintains its free space and inode, including the following information:
Ø Super-block: descriptive information on the whole system;
Ø Free space management;
Ø Allocation and record management of inode.
Super-block records all metadata in the AG and core metadata includes the following:
Ø Block size: Size of block used in the file system and the number of blocks in the whole system that are holding data and metadata;
Ø Sector size: Specifying the size of a sector on the underlying disc and the minimum alignment granularity of the data;
Ø AG_blocks/AG_count: Number of blocks contained in an AG in the system and number of AGs in the whole system;
Ø Inode size / inop block: Size of inode and number of inode contained in a block;
Ø Log start/log blocks: When the same disc is used to store all XFS journals, these two values represent the first block used to store journal and the number of blocks used to store logs;
Ø Icount / ifree: number of allocated inode and number of inode remaining available, which is only maintained in the AG Primary Superblock.
It should be noted that the byte order used in XFS file system is big-endian order and all metadata information structure of the AG is stored in Super book, as shown in Picture 2.
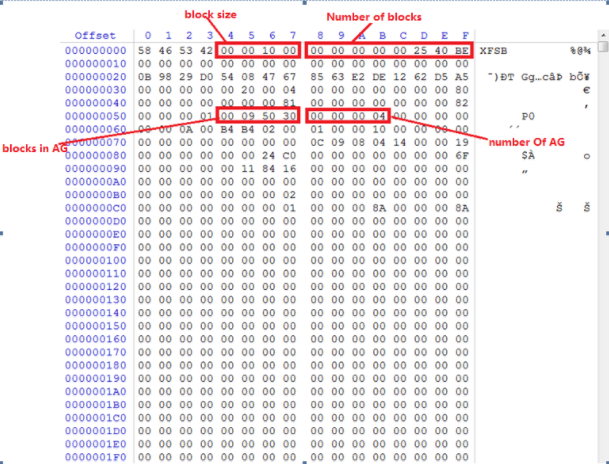
Picture 2
When the XFS stores data file, an extended list is generated to store serial numbers of block structures occupied and entries are recorded in sequence to contain information on the serial numbers of each block address and the number of blocks occupied. Picture 3 uses IRIX 5.3 version of the XFS file system as an example to demonstrate the basic structure of the file list.
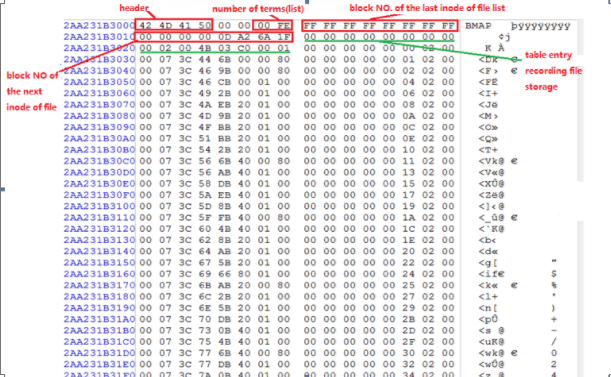
Picture 3
In XFS file system, the length of a block equals the length of each file chain with a structure as shown in Picture 4.
| Header | Level of File
Chain List |
No of
Entries |
Inode
(Left) |
Inode
(Right) |
Entry Data*N |
Picture 4
The file signature is 0x424D4150 with the length of 4 bytes and the following 2 bytes indicate the current file list level. The value of the next two bytes indicates the number of entries in the current file list, followed by addresses of the left and right nodes, each of which occupies 8 bytes. Data stored next are entry data with each entry occupies 16 bytes, its contents represents all 00 throughout the 16 bytes if the entry is unoccupied.
Each entry records block address information with its structure as shown in Picture 5.
| Flag Bit | Offset Address of Entry Data | AG No of Block & Offset | No of Blocks |
Picture 5
Unit of storage structure within an entry is bitten and each entry has the length of 16 bytes, which can be converted to the bit as 16*8=128bit. The value of 1bit offset of each entry is the mark bit of this entry; the value of 2bit to 55bit offset is the offset number of blocks of the recorded block data in the file; the value of 56bit to 107bit offset is the block address of the file, including the AG number of the occupied block and its offset number in the AG. Offset the number of the block in the AG occupies lower bit in the structure, its length equals the value of 0x7Cbit offset in the XFS file system; thus AG number of the block locates in higher bit, 56bit~107bit offset, and its length equals the length of offset number of 52 cut block in the AG. The value of 108bit to 128bit offset is the number of blocks used by the file.
III Methods for Recovering Fragmented Files
Through an in-depth analysis of the XFS file system it is found that when the blocks allocated to store a file are inconsistent, the system will use extend file chain to record file storage information. Comparison of the files before and after the deletion indicates that the deletion will only erase inode note information, but not the file chain information (Picture 6), which provides theoretical support for data recovery.

Picture 6
When the XFS stores data file, an extended list is generated to store serial numbers of block structures occupied and entries are recorded in sequence to contain information on the serial numbers of each block address and the number of blocks occupied. Based on this characteristic, experts only need to locate the list that records information on occupied block number to search data and to extract data contents of the corresponding block in accordance with the information recorded in the list. Data reorganization can be done by following the sequence of the list records, which completes the reallocation of file fragments based on XFS file system.
IV Process of Fragmented Files Recovery Based on XFS File System
The process of fragmented files recovery based on XFS file system includes the following steps:
1. Load and parse disc sector information
Load the disc, access the sector of superblocks in the AG and parse this sector. Contents need to be parsed include block size, the total number of blocks, number of blocks contained in the AG, and offset value of each block in the AGG. Specifically, superblock locates in the first sector of the AG data and value of 0x04~0x07 offset indicates block size, value of 0x08~0x0F offset indicates total number of blocks, value of 0x54~0x57 indicates the block number contained in each AG, and value of 0x7C offset indicates offset number of THE block from the listed entry in the AG.
2. Match File List Structure
Access the size of each file list, which is also the value of block size. Divide data in the entire hard drive into several blocks and decide whether a block matches the following features of file list structure:
Feature 1: file list header as 0x424D4150;
Feature 2: the next 2 bytes indicate the level of the file list, its value range as 0~255;
Feature 3: the next 2 bytes indicates number of entries in the file list, which should be less than the total number of blocks recorded in the superblock;
Feature 4: the next 8 bytes indicates status of former data contents from files recorded in the file list, which should be less than the total number of blocks recorded in the superblock;
Feature 5: the next 8 bytes indicates the status of latter data contents from files recorded in the file list, which should be less than the total number of blocks recorded in the superblock.
3. Parse file list structure
First, use the aforementioned feature 4 to identify whether the file recorded in the file list has data recorded before it in the file list. If the value of address explained in feature 4 is -1, then there is no former file data and this file list is the root node in file storage. If the value is not -1, then this value indicates the corresponding block number of the file list of the files before the current file list address, and parse the file list structure using methods mentioned above. Using the same rule to identify whether there is any data recorded after the current file in the file list. Similarly, data of each entry in the file list can be parsed by accessing block number and number of blocks occupied in accordance with entry structure characteristics.
4. Access Address Data of the Corresponding Block
According to the sequence of the file list, access address data of the corresponding block of each entry on the basis of information got from the former step.
5. Reorganize into New Files
Using information parsed in step 4, connections between different file lists and sequence of entries, organize address data of blocks recorded in the entries into a new file.
6. Traverse All Hard Drive Sectors
After parsing of values recorded in a file list is successfully done, continue the search of file list structures and decide whether the file list is occupied. If occupied, move forward; if not, parse the file list by repeating steps 2 to 5 until all hard drive sectors are searched and parse work done if applicable.
By going through all the above steps, data reorganization and recovery from file fragments based on XFS file system can be achieved.
V Conclusion
In this issue, forensic experts from SalvationDATA introduced a method that can be also used to realize data reorganization and recovery from video data deleted based on XFS file system. It does not only support the extraction of video data deleted, but also its reorganization. This technology is currently used in our products as DRS(Data Recovery System) and VIP (Video Investigation Portable).
